The study begins by considering an abstract object (cellular automaton) able of moving -by arbitrary decision- between two given fixed positions. That is, at each clock step, it can change position or remain stationary in its current position. This object, which we call an Arbitrary Oscillator (ArbO), cannot evolve indefinitely since it may encounter ‘end-of-life’ events, which are also random. If we place quantitative limits on the number of arbitrary events and impose that the life cycle of ArbO must end in any case, we can use Fermi statistics to find the most probable distribution of fatal events along the possible sequences of choices. This distribution is represented by a recursive function that can be calculated for each total number of possible ‘life/death’ choices, which we will call Total Cases (TC). By means of a time-scale adjustment, we have associated the distribution curves of ArbO ‘fatal’ events with the demographic mortality curves (dx and qx data) of populations in the case of Italy. To better study the properties of the statistical function thus found, we attempted a continuous transposition of the recursive equation, seeking solutions to the differential equation linkable with it. With a continuous analytical expression, the characteristics of this statistical distribution can be studied more effectively. Similarities and differences with demographic mortality curves have been highlighted, attempting to explain the latter as overlaps of curves with different TC parameters. Implications with life span and more general life cycle concepts are outlined. A correlation with a more recent study using a multi-omics approach is also pointed out.
| Published in | Science Journal of Applied Mathematics and Statistics (Volume 13, Issue 4) |
| DOI | 10.11648/j.sjams.20251304.12 |
| Page(s) | 76-91 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Cellular Automata, Fermi Statistics, Logistic Distribution, Demographic Mortality, Lifespan
Years interval | r | m | v | Q | ISTAT -2019 1000 x qx | ISTAT-2019 dx | ISTAT-1974 dx |
|---|---|---|---|---|---|---|---|
Up to 4 years | 1 | 0 | 2 | 2 | 3,3453 | 335 | 2735 |
5-9 | 2 | 0 | 4 | 4 | 0,36563 | 36 | 180 |
10-14 | 3 | 0 | 8 | 8 | 0,43792 | 44 | 170 |
15-19 | 4 | 0 | 16 | 16 | 0,99425 | 99 | 334 |
20-24 | 5 | 0 | 32 | 32 | 1,429 | 142 | 385 |
25-29 | 6 | 0 | 64 | 64 | 1,63059 | 162 | 368 |
30-34 | 7 | 0 | 128 | 128 | 1,9993 | 198 | 505 |
35-39 | 8 | 1 | 255 | 255 | 2,86143 | 283 | 686 |
40-44 | 9 | 3 | 507 | 509 | 4,69355 | 463 | 1128 |
45-49 | 10 | 10 | 1003 | 1014 | 7,33727 | 721 | 1863 |
50-54 | 11 | 40 | 1966 | 2007 | 11,46247 | 1118 | 2799 |
55-59 | 12 | 155 | 3778 | 3933 | 18,46051 | 1780 | 4470 |
60-64 | 13 | 572 | 6984 | 7556 | 29,60728 | 2801 | 6265 |
65-69 | 14 | 1966 | 12002 | 13968 | 47,28093 | 4341 | 9089 |
70-74 | 15 | 5924 | 18079 | 24003 | 75,57279 | 6611 | 12542 |
75-79 | 16 | 14315 | 21843 | 36158 | 130,66618 | 10566 | 16581 |
80-84- | 17 | 24780 | 18906 | 43686 | 227,36915 | 15984 | 17535 |
85-89 | 18 | 27370 | 10441 | 37811 | 404,2388 | 21956 | 13839 |
90-94 | 19 | 17537 | 3345 | 20882 | 621,66989 | 20117 | 6806 |
95-99 | 20 | 6107 | 582 | 6690 | 798,55747 | 9776 | 1591 |
100-104 | 21 | 1112 | 53 | 1165 | 931,49213 | 2297 | 127 |
105-109 | 22 | 104 | 2 | 106 | 986,30673 | 167 | 2 |
110-114 | 23 | 5 | 0 | 5 | 998,26306 | 2 | 0 |
115-119 | 24 | 0 | 0 | 0 | 999,85919 | 0 | 0 |
Total |
| 100001 | 100000 | 200002 |
| 99999 | 100000 |
ArbO | Arbitrary Oscillator |
EoL | End of Life |
FWHM | Full Width at Half Maximum |
| [1] | L. A. Gavrilov and N. S. Gavrilova, “The Biology of Life Span: a Quantitative Approach” Center on Aging NORC and The University of Chicago, Illinois, USA, slide presentation available at: |
| [2] | D. Makowiec, D. Stauffer and M. Zieliński, “Gompertz law in simple computer model of ageing of biological population”, |
| [3] | A. Racco, M. Argollo de Menezes and T. J. Penna “Search for an unitary mortality law through a theoretical model for biological ageing”, |
| [4] | M. D. Pascariu, A. Lenart & V. Canudas-Romo (2019) “The maximum entropy mortality model: forecasting mortality using statistical moments”, Scandinavian Actuarial Journal, 2019: 8, 661-685, |
| [5] | A. Boulougari, K. Lundengård, M. Rančić, S.Silvestrov, S. Suleiman & B. Strass (2019) “Application of a power-exponential function-based model to mortality rates forecasting”, Communications in Statistics: Case Studies, Data Analysis and Applications, 5: 1, 3-10, |
| [6] | S. J. Clark “A General Age-Specific Mortality Model With an Example Indexed by Child Mortality or Both Child and Adult Mortality”, Demography. 2019 June; 56(3): 1131-1159. |
| [7] | ISTAT Web site, |
| [8] | SQU Systems, Web site managed by the author and devoted to diophantine S equation systems. |
| [9] | E. Fermi, “Molecules, Crystals and Quantum Statistics”, W. A. Benjamin, 1966, pag. 264 and subseq. |
| [10] | P. Richmond and B. M. Roehner “Predictive implications of Gompertz’s law.”, |
| [11] | L. A. Gavrilov and N. S. Gavrilova, “Mortality Measurement at Advanced Ages: a Study of the Social Security Administration Death Master File”, North American Actuarial Journal. 15(3): 432-447. |
| [12] | Nicolas Bacaer, Histoires des mathematiques et de populations ed. Cassini, Paris, 2008. |
| [13] | S. Méléard, “Modèles aléatoires en Ecologie et Evolution”, Springer. |
| [14] | K., Henderson| M. Loreau “An ecological theory of changing human population dynamics”, People and Nature. 2019; 1: 31-43. |
| [15] | M. Ausloos, “Gompertz and Verhulst frameworks for growth AND decay description”, arXiv: 1109.1269v2. |
| [16] | G. Alberti “More on the mortality conjecture: the components of demographic mortality” |
| [17] | Xiaotao Shen, Chuchu Wang, Xin Zhou, Wenyu Zhou, Daniel Hornburg, Si Wu & Michael P. Snyder “Nonlinear dynamics of multi-omics profiles during human aging”, Nature Aging, |
APA Style
Alberti, G. (2025). Fermi Statistics Method Applied to Model Macroscopic Demographic Data. Science Journal of Applied Mathematics and Statistics, 13(4), 76-91. https://doi.org/10.11648/j.sjams.20251304.12
ACS Style
Alberti, G. Fermi Statistics Method Applied to Model Macroscopic Demographic Data. Sci. J. Appl. Math. Stat. 2025, 13(4), 76-91. doi: 10.11648/j.sjams.20251304.12
AMA Style
Alberti G. Fermi Statistics Method Applied to Model Macroscopic Demographic Data. Sci J Appl Math Stat. 2025;13(4):76-91. doi: 10.11648/j.sjams.20251304.12
@article{10.11648/j.sjams.20251304.12,
author = {Giuseppe Alberti},
title = {Fermi Statistics Method Applied to Model Macroscopic Demographic Data},
journal = {Science Journal of Applied Mathematics and Statistics},
volume = {13},
number = {4},
pages = {76-91},
doi = {10.11648/j.sjams.20251304.12},
url = {https://doi.org/10.11648/j.sjams.20251304.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.sjams.20251304.12},
abstract = {The study begins by considering an abstract object (cellular automaton) able of moving -by arbitrary decision- between two given fixed positions. That is, at each clock step, it can change position or remain stationary in its current position. This object, which we call an Arbitrary Oscillator (ArbO), cannot evolve indefinitely since it may encounter ‘end-of-life’ events, which are also random. If we place quantitative limits on the number of arbitrary events and impose that the life cycle of ArbO must end in any case, we can use Fermi statistics to find the most probable distribution of fatal events along the possible sequences of choices. This distribution is represented by a recursive function that can be calculated for each total number of possible ‘life/death’ choices, which we will call Total Cases (TC). By means of a time-scale adjustment, we have associated the distribution curves of ArbO ‘fatal’ events with the demographic mortality curves (dx and qx data) of populations in the case of Italy. To better study the properties of the statistical function thus found, we attempted a continuous transposition of the recursive equation, seeking solutions to the differential equation linkable with it. With a continuous analytical expression, the characteristics of this statistical distribution can be studied more effectively. Similarities and differences with demographic mortality curves have been highlighted, attempting to explain the latter as overlaps of curves with different TC parameters. Implications with life span and more general life cycle concepts are outlined. A correlation with a more recent study using a multi-omics approach is also pointed out.},
year = {2025}
}
TY - JOUR T1 - Fermi Statistics Method Applied to Model Macroscopic Demographic Data AU - Giuseppe Alberti Y1 - 2025/12/11 PY - 2025 N1 - https://doi.org/10.11648/j.sjams.20251304.12 DO - 10.11648/j.sjams.20251304.12 T2 - Science Journal of Applied Mathematics and Statistics JF - Science Journal of Applied Mathematics and Statistics JO - Science Journal of Applied Mathematics and Statistics SP - 76 EP - 91 PB - Science Publishing Group SN - 2376-9513 UR - https://doi.org/10.11648/j.sjams.20251304.12 AB - The study begins by considering an abstract object (cellular automaton) able of moving -by arbitrary decision- between two given fixed positions. That is, at each clock step, it can change position or remain stationary in its current position. This object, which we call an Arbitrary Oscillator (ArbO), cannot evolve indefinitely since it may encounter ‘end-of-life’ events, which are also random. If we place quantitative limits on the number of arbitrary events and impose that the life cycle of ArbO must end in any case, we can use Fermi statistics to find the most probable distribution of fatal events along the possible sequences of choices. This distribution is represented by a recursive function that can be calculated for each total number of possible ‘life/death’ choices, which we will call Total Cases (TC). By means of a time-scale adjustment, we have associated the distribution curves of ArbO ‘fatal’ events with the demographic mortality curves (dx and qx data) of populations in the case of Italy. To better study the properties of the statistical function thus found, we attempted a continuous transposition of the recursive equation, seeking solutions to the differential equation linkable with it. With a continuous analytical expression, the characteristics of this statistical distribution can be studied more effectively. Similarities and differences with demographic mortality curves have been highlighted, attempting to explain the latter as overlaps of curves with different TC parameters. Implications with life span and more general life cycle concepts are outlined. A correlation with a more recent study using a multi-omics approach is also pointed out. VL - 13 IS - 4 ER -
Independent Researcher, Como, Italy
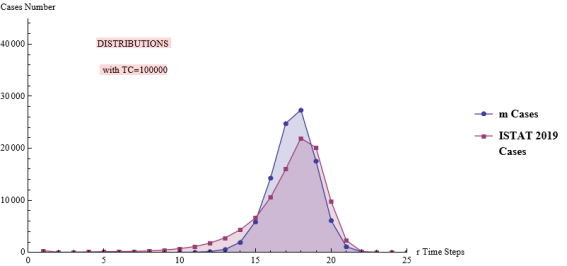
Figure 1. m function & mortality distribution.

Figure 2. The Arbitrary Oscillator.
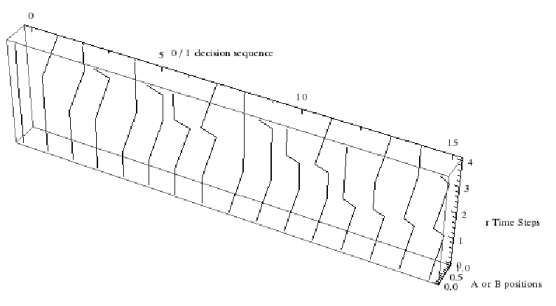
Figure 3. Path-space of the Arbitrary Oscillator for 4 steps of time decisions.
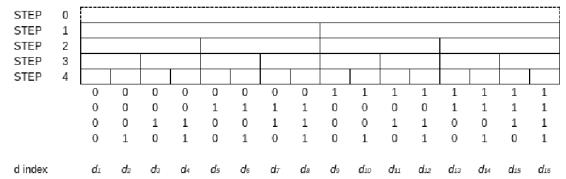
Figure 4. Possible choices sequences.
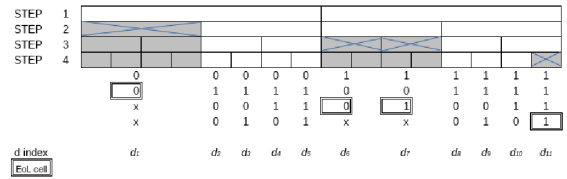
Figure 5. EoL events.
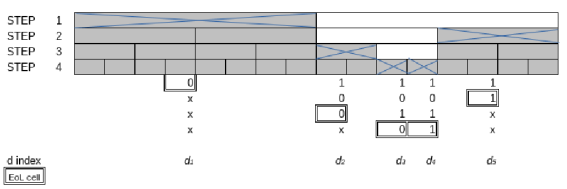
Figure 6. A fully ended life cycle of the arbitrary oscillator.
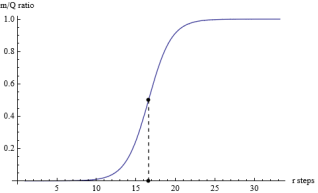
Figure 7. (mr /Qr) Logistic shape for TC = 100000.
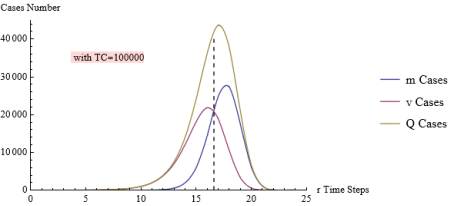
Figure 8. Interpolated m, v, Q curves.
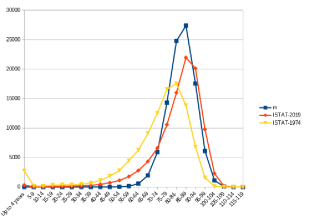
Figure 9. Graphic comparison of m, ISTAT74, ISTAT19 curves vs five years intervals.
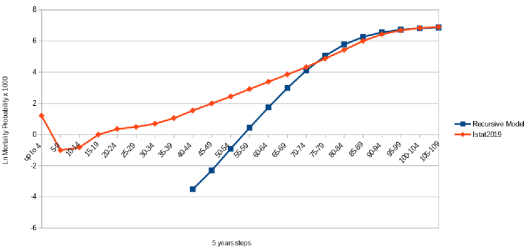
Figure 10. Log mortality probability given by recursive model and ISTAT2019 data.
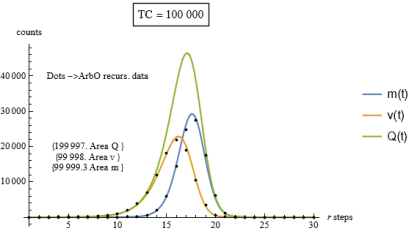
Figure 11. Comparison between the continuous curves m,v,Q and the recursive ArbO discrete data, TC=100 000.
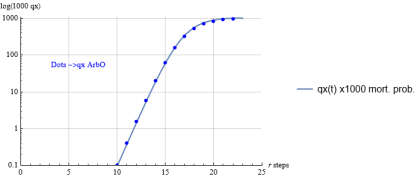
Figure 12. Comparison between the continuous qx curve and the ArbO discrete data, TC=100 000.
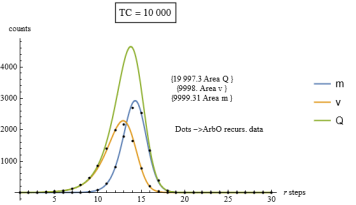
Figure 13. Comparison between the continuous curves m,v,Q and the recursive ArbO discrete data, TC=10 000.
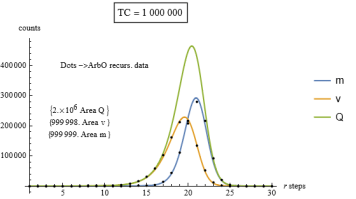
Figure 14. Comparison between the continuous curves m,v,Q and the recursive ArbO discrete data, TC=1 000 000.
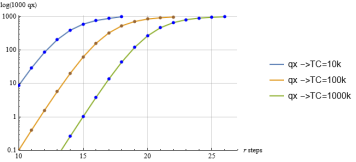
Figure 15. Theoretical qx(t) values computed with the ArbO model for different TC parameter values.
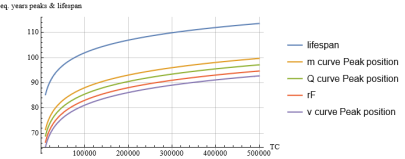
Figure 16. Peak positions for the continuous curves m,v,Q vs TC values.
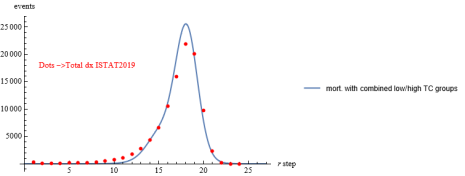
Figure 17. ISTAT2019 mortality data over a curve combined by sub-groups with different TC.
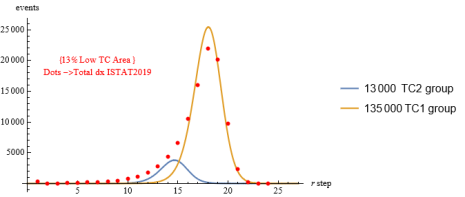
Figure 18. ISTAT2019 mortality data and the two sub-groups curves to be summed to give the combined total curve.
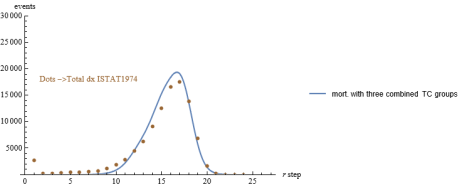
Figure 19. ISTAT1974 mortality data over a curve combined by sub-groups with different TC.
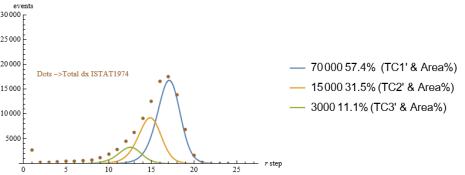
Figure 20. ISTAT1974 mortality data and the three component sub-groups curves to be summed to give the combined total curve.
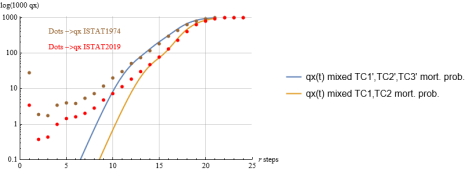
Figure 21. ISTAT1974 and 2019 mortality probability compared with qx(t) mixed curves coming from combining three groups or two groups respectively (same quotas as in Figures 20 and 18).

